Please select your location and preferred language where available.
Zero-shot Neural Passage Retrieval with a Pre-trained Language Model
May 17, 2023
Kioxia is developing Memory-Centric AI*1 that can search through and reference its memory base. We present our recent research result on passage retrieval task, one of the things we are working on.
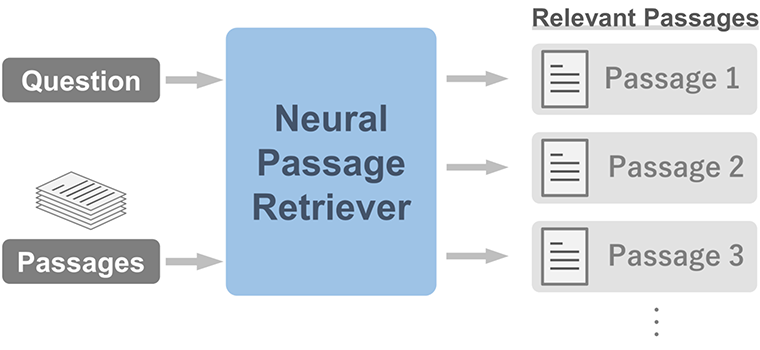
Passage retrieval is the task of finding relevant passages corresponding to a given question (Fig.1). It has been shown that pre-trained*2 neural language models can perform as a neural passage retriever when fine-tuned*3 for retrieval. However, the existing neural retrievers do not perform well especially when a named entity (such as a name of person) in a question is a dominant clue for retrieval[1]. To address the issue, several approaches have been proposed to modify the method of fine-tuning for retrieval.
In contrast, our idea is opposite to the conventional one: employing a pre-trained language model without fine-tuning. Our intuition is that; a pre-trained language model should have rich knowledge including named entities and the rich knowledge would be forgotten during fine-tuning*4, resulting in poor retrieval performance on entity-centric questions. However, it has not been clear how to leverage a pre-trained language model for retrieval without fine-tuning.
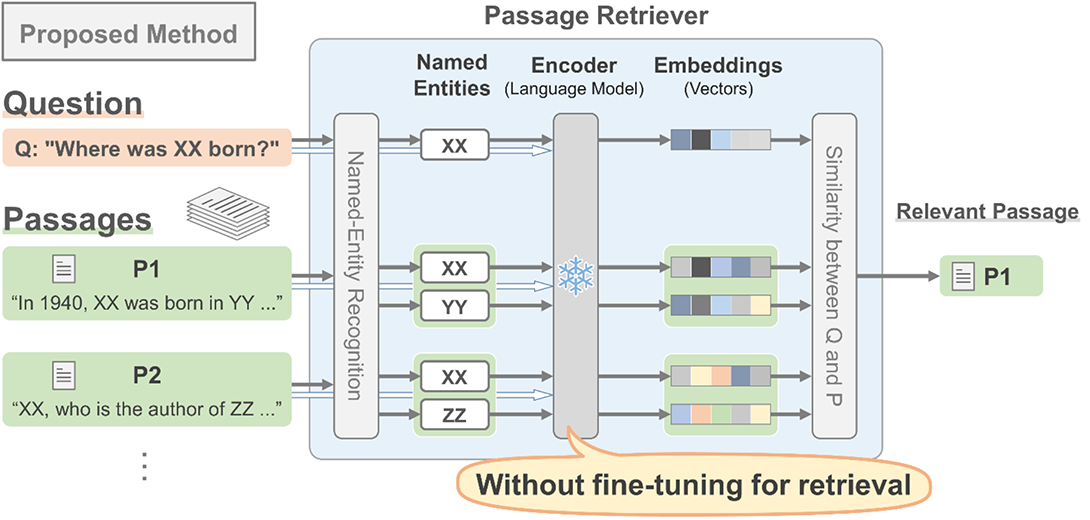
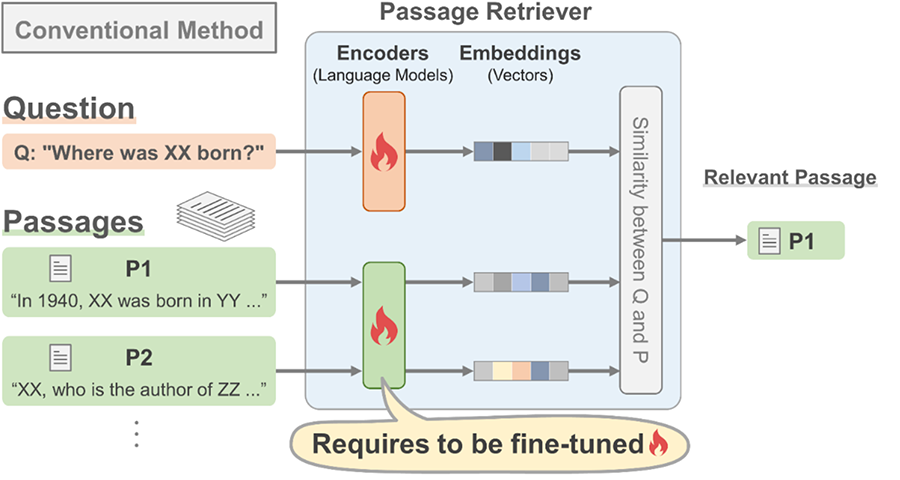
We propose a method that allows a pre-trained language model to be used for retrieval without fine-tuning (Fig.2). A pre-trained language model encodes the named entities extracted from a question and passages into contextualized representations (vectors). Our method requires only one language model, while conventional methods require to fine-tune two language models, one for questions and the other for passages (Fig.3).
Our proposed method achieves almost comparable performance (67.1%) to a state-of-the-art retriever (74.5%) and shows the best performance for two relations out of 24 relations, when evaluated on the question-answering dataset [1] consisting of a total of 24 relations (e.g., place of birth) [2, 3]. Conventional methods require creation of a dataset in a specific domain, such as medical domain, to build a neural retriever that works in the domain. Our method, on the other hand, demonstrates the possibility of retrieval without building the additional dataset, as long as the language model is pre-trained in the domain.
We presented this result at Workshop on Knowledge Augmented Methods for Natural Language Processing (KnowledgeNLP), in conjunction with AAAI-23 (the Thirty-Seventh AAAI Conference on Artificial Intelligence).
*1 Memory-Centric AI, Part I: How Kioxia’s Top Engineers Are Developing an AI That Relies on Memory
https://www.kioxia.com/en-jp/insights/in-the-pipeline-memory-centric-ai-1-202207.html
Memory-Centric AI, Part II: An Internet of Memories: Brainstorming Uses for Memory-Centric AI
https://www.kioxia.com/en-jp/insights/in-the-pipeline-memory-centric-ai-2-202207.html
Kioxia Presented Image Classification System Deploying Memory-Centric AI with High-capacity Storage at ECCV 2022
https://www.kioxia.com/en-jp/about/news/2022/20221102-1.html
Development of Image Classification System Deploying Memory-Centric AI with High-capacity Storage
https://www.kioxia.com/en-jp/rd/technology/topics/topics-39.html
*2 Pre-training: first training of a language model on a large dataset to perform as a language-specific AI that can understand contexts or identify the meaning of words in sentences.
*3 Fine-tuning: additional training for a pre-trained language model to perform a specific natural language processing task such as passage retrieval, using a task-specific dataset. The size of the dataset for fine-tuning is usually much smaller than that for pre-training. The dataset used for retrieval fine-tuning consists of a set of questions paired with the relevant passages to each question.
*4 Fine-tuning can destroy knowledge in a pre-trained model, which has been obtained during pre-training.
Reference
[1] Sciavolino, C., Zhong, Z., Lee, J., & Chen, D. (2021). Simple Entity-Centric Questions Challenge Dense Retrievers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 6138-6148).![]()
[2] Hoshi, Y., Miyashita, D., Morioka, Y., Ng Y., Torii, O., & Deguchi, J. (2023). Can a Frozen Pretrained Language Model be used for Zero-shot Neural Retrieval on Entity-centric Questions? Workshop on Knowledge Augmented Methods for Natural Language Processing, in conjunction with AAAI 2023.![]()
[3] Hoshi, Y., Miyashita, D., Morioka, Y., Ng Y., Torii, O., & Deguchi, J. (2023). arXiv preprint arXiv:2303.05153.![]()

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.