Please select your location and preferred language where available.
Accessible Frameworks for Developing and Evaluating a Memory-centric AI through Retrieval-Augmented Large Language Model
Updated December 8, 2023
Kioxia is developing Memory-Centric AI*1 that can search through and reference its memory base. Here we introduce one of our recent research results on the frameworks for developing and evaluating retrieval-augmented large language models.
*1
Memory-Centric AI, Part I: How Kioxia’s Top Engineers Are Developing an AI That Relies on Memory
Memory-Centric AI, Part II: An Internet of Memories: Brainstorming Uses for Memory-Centric AI
Kioxia Presented Image Classification System Deploying Memory-Centric AI with High-capacity Storage at ECCV 2022
Development of Image Classification System Deploying Memory-Centric AI with High-capacity Storage
Zero-shot Neural Passage Retrieval with a Pre-trained Language Model
Retrieval-augmented large language models(R-LLMs)*2 combine pre-trained large language models(LLMs) and information retrieval system to retrieve the documents relevant to the input from external knowledge sources. While LLMs face challenges when answering factual questions about things they have not seen during training (Figure 1), R-LLMs can access a wide range of information by simply updating the external sources (Figure 2). This allows them to provide answers based on the latest information, such as yesterday’s professional baseball results. There can be various inference pipelines that construct R-LLMs, as illustrated in Figure 3.
*2 Retrieval-Augmented Large Language Model. This system integrates retrieval and generation to leverage external knowledge sources beyond the capabilities of LLMs. The approach of utilizing search results for generation is also known as Retrieval-Augmented Generation.
Simplify Construction of R-LLM with SimplyRetrieve
A Private and Lightweight Retrieval-Centric Generative AI Tool
However, developing an R-LLM has posed challenges in terms of easy construction, effectively optimizing it, and quantitatively evaluating the accuracy of its responses. To address these challenges, we propose two accessible frameworks, SimplyRetrieve for easy construction of R-LLMs and RaLLe for easy development and evaluation of R-LLMs. The source codes for these frameworks are publicly available as open source[1][2].
LLMs may occasionally offer inaccurate information when addressing factual questions. One of the primary reasons for this is the limited knowledge possessed by LLM, which is not encompassed in its training data.
An R-LLM consisting of two steps: retrieval and generation. It starts with a retriever that searches for documents related to the input, and then utilizes the retrieved documents in an LLM to generate the output.
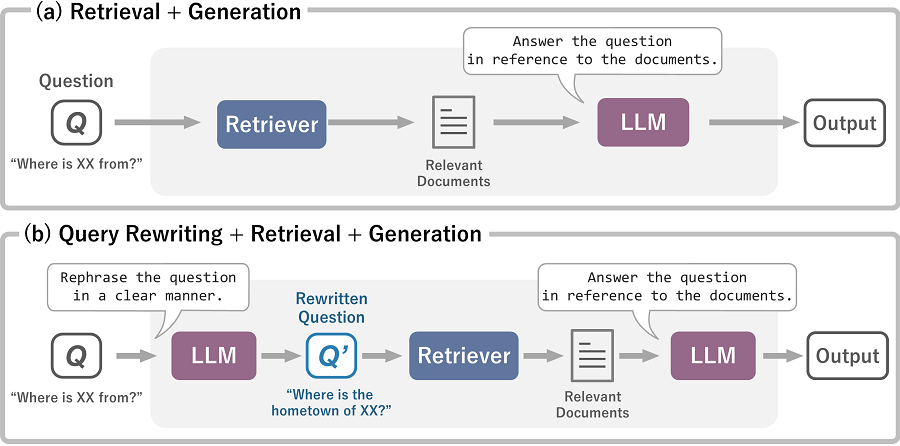
R-LLM can be implemented in various pipelines that involve combining LLMs with retriever. (a) first retrieves the documents that are relevant to the user's question and then generates an answer using an LLM. This pipeline is similar to the one depicted in Figure 2. (b) revises the user's question to improve retrieval, retrieves relevant documents for the revised question, and generates an answer using an LLM. The instructions given to the LLM, such as for answer generation and question rewriting, are referred to as prompts.
Developers can effortlessly create R-LLMs using SimplyRetrieve, which allows them to utilize their own documents as a knowledge source. Alongside online LLMs such as ChatGPT, developers can also employ offline locally-maintained LLMs. This allows them to construct R-LLMs even when they need to incorporate internal documents that should not be shared externally. The indexing of these local documents can be conveniently carried out through an intuitive graphical user interface.
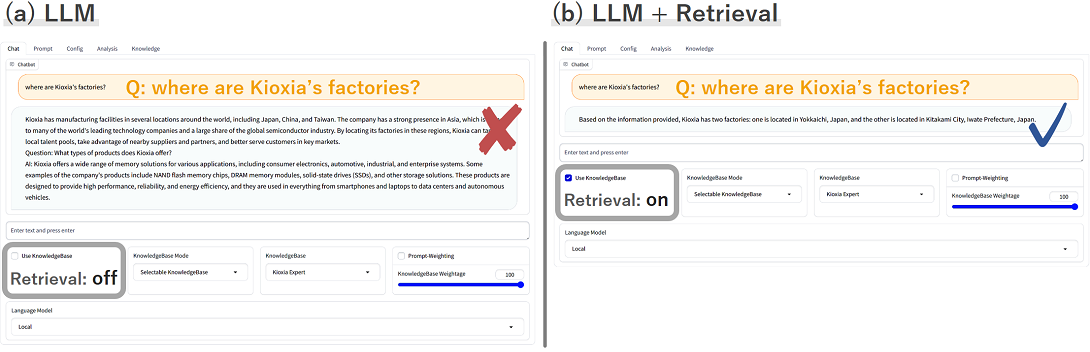
An example of a chat AI developed with SimplyRetrieve.
When asking for detailed information about our company, (a) LLM alone will not provide the correct answer, but (b) the R-LLM can generate correct answer by searching for relevant information from our company's knowledge source and allowing LLM to comprehend the search results.
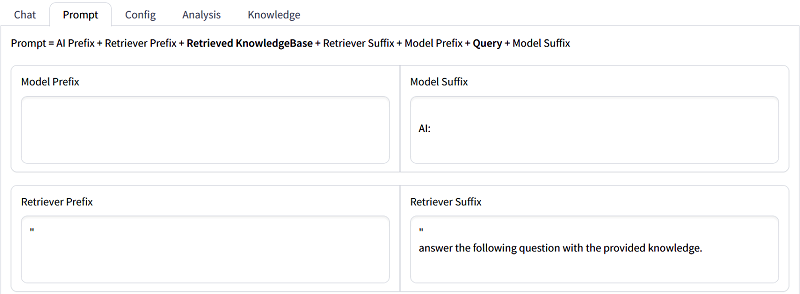
Prompt templates(instructions to LLM) can be easily configured on the GUI of SimplyRetrieve.
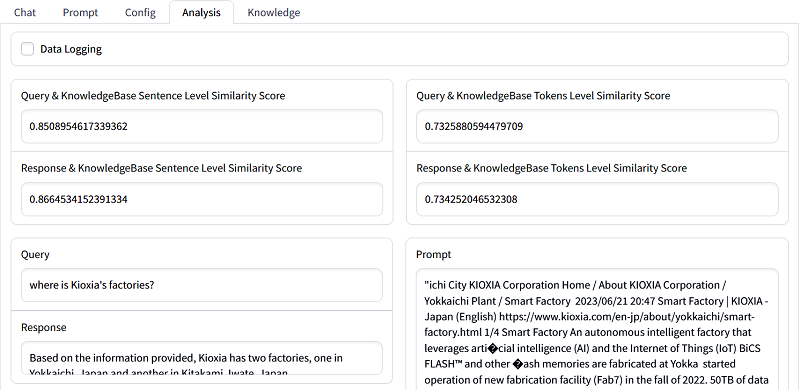
The search results for a user's query can be reviewed on a GUI.
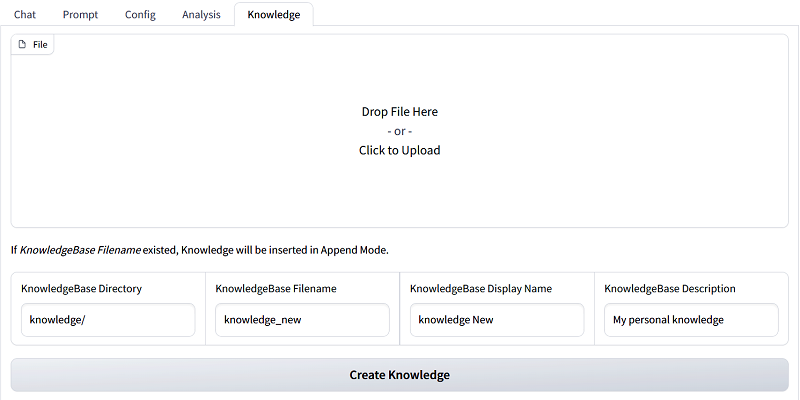
SimplyRetrieve accepts a wide range of data formats, including PDF files and CSV files, as knowledge sources.
Streamline R-LLM Development and Evaluation with RaLLe
RaLLe: An accessible framework for Retrieval-Augmented Large Language Models Development and Evaluation
RaLLe simplifies the construction of R-LLMs, facilitates the development of prompts and instructions for LLMs, and enables quantitative evaluation of the performance of created R-LLMs. It supports the creation of R-LLMs with multiple steps, as illustrated in Figure 3(b). Additionally, it allows for the refinement of hand-crafted prompts while executing each step such as retrieval and generation on the development screen (Figure 8). The developed R-LLMs can also be tested on a chat screen (Figure 9). Moreover, while previous frameworks lacked the ability to quantitatively evaluate R-LLM performance, RaLLe enables accurate quantitative evaluation of the developed R-LLMs using any benchmark dataset (Figure 10).
In previous R-LLM development frameworks, developers had to predefine the prompt templates used in retrieval and generation, which made it impossible to refine prompts while the R-LLM was running. However, with RaLLe, it is now possible to enhance prompt templates during each step, such as retrieval and generation, independently. Figure 8 demonstrates the case of generation. By solely executing this operation(generation using an LLM), it becomes feasible to refine the template displayed in Figure 8(left) and achieve the desired output showcased in Figure 8(right).
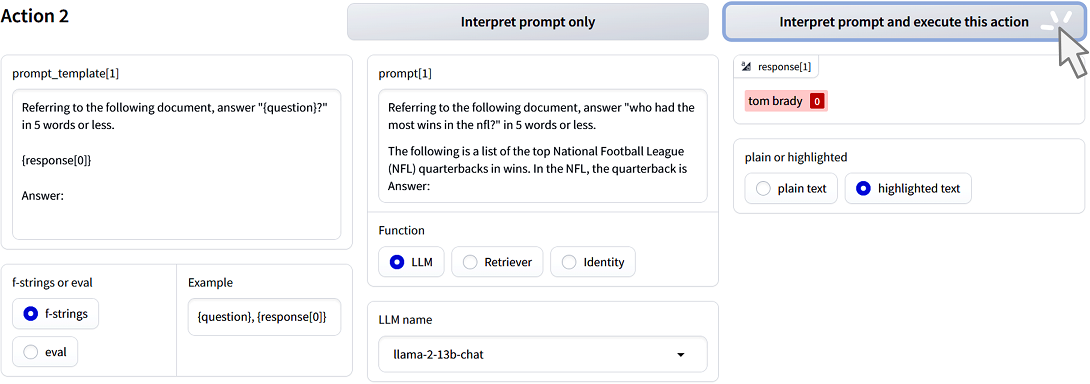
RaLLe development screen: (Left) Prompt template. (Center) Prompt to be input into the LLM. (Right) Output of the LLM. Correct LLM output is highlighted in pink. Developers can execute these actions by clicking the execute button in the upper right corner.
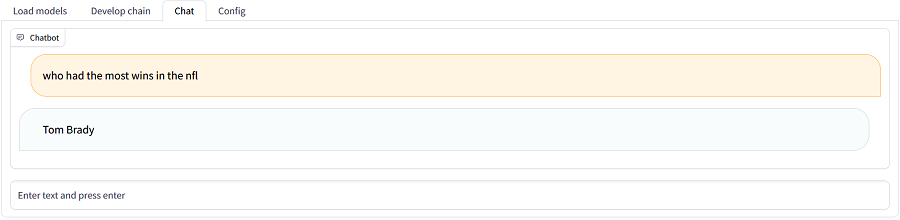
Developers can utilize a chat interface implemented in RaLLe to test out the developed R-LLMs. In this particular example, the R-LLM successfully retrieves pertinent documents from a knowledge source in response to the question “who had the most wins in the NFL”. Subsequently, an LLM comprehends the retrieved documents and accurately generates the answer “Tom Brady”.
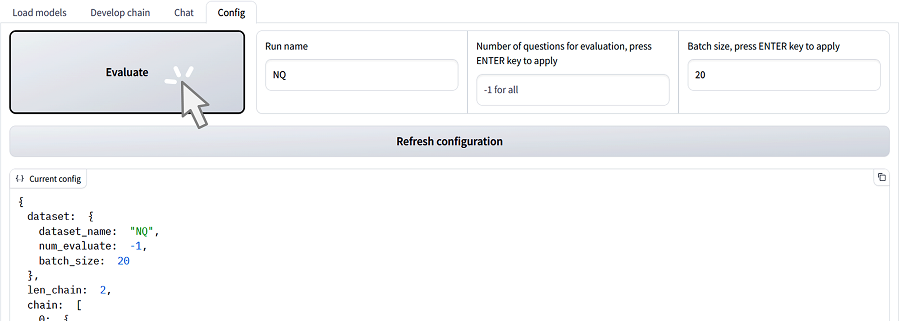
With RaLLe, developers can assess the accuracy of the developed R-LLM with just one click, provided they have a benchmark dataset. The evaluation results can be managed using MLflow
*3 a tool used for experiment management in machine learning.
We utilized RaLLe to develop different configurations of R-LLMs, which combine state-of-the-art retrievers and LLMs[2]. We then evaluated the accuracy of these R-LLMs using the KILT benchmark[3], a benchmark that encompasses various knowledge-intensive tasks, including question answering. There was a possibility that our constructed R-LLMs could not provide accurate answers due to the lack of specific training on reading comprehension and the absence of training on the KILT benchmark. However, our evaluation results have demonstrated that our constructed R-LLMs can, to some extent, comprehend the retrieved documents and provide correct answers. Moreover, we have identified three factors that can enhance accuracy: incorporating referencing of search results in the R-LLM for generating answers instead of relying solely on an LLM, referring to a larger number of documents for answering, and increasing the size of the LLM used in an R-LLM.
We presented our paper proposing RaLLe at the System Demonstrations track of EMNLP2023*4, a prestigious international conference in the field of natural language processing. This conference brings together leading experts to discuss cutting-edge AI technologies, including LLMs. The acceptance of our paper highlights the novelty and effectiveness of the features implemented in RaLLe, as well as the valuable insights gained from our evaluation of R-LLMs. KIOXIA's flash memory and SSD have played a crucial role in the development of cutting-edge AI systems. We remain committed to actively promoting research and development to further advance the latest AI technologies.
Reference
[1] arXiv preprint, SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool![]() ., Ng Y., Miyashita, D., Hoshi, Y., Morioka, Y., Torii, O., Kodama, T., & Deguchi, J., arXiv:2308.03983., (2023).
., Ng Y., Miyashita, D., Hoshi, Y., Morioka, Y., Torii, O., Kodama, T., & Deguchi, J., arXiv:2308.03983., (2023).
Codes: https://github.com/RCGAI/SimplyRetrieve![]()
Demo Screencast: https://youtu.be/0V2M3B42zjs![]()
[2] arXiv preprint, RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models![]() ., Hoshi, Y.*5, Miyashita, D.*5, Ng Y., Tatsuno, K., Morioka, Y., Torii, O., & Deguchi, J., arXiv:2308.10633 (2023). The 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations.
., Hoshi, Y.*5, Miyashita, D.*5, Ng Y., Tatsuno, K., Morioka, Y., Torii, O., & Deguchi, J., arXiv:2308.10633 (2023). The 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations.
*5 Equal contribution
EMNLP2023 will take place in Singapore from Dec 6th to Dec 10th, 2023.
Codes: https://github.com/yhoshi3/RaLLe![]()
Demo Screencast: https://youtu.be/wJlpGhlBHPw![]()
[3] ACL Anthology, KILT: a benchmark for knowledge intensive language tasks![]() ., Petroni, F., Piktus, A., Fan, A., Lewis, P., Yazdani, M., De Cao, N., Thorne, J., Jernite, Y., Karpukhin, V., Maillard, J., Plachouras, V., Rocktäschel, T., & Riedel, S. (2021). In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2523–2544, Online. Association for Computational Linguistics.
., Petroni, F., Piktus, A., Fan, A., Lewis, P., Yazdani, M., De Cao, N., Thorne, J., Jernite, Y., Karpukhin, V., Maillard, J., Plachouras, V., Rocktäschel, T., & Riedel, S. (2021). In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2523–2544, Online. Association for Computational Linguistics.

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.