Please select your location and preferred language where available.
Improving Performance of Pre-Trained Vision Models via Inference-Time Attention Engineering
July 8, 2025
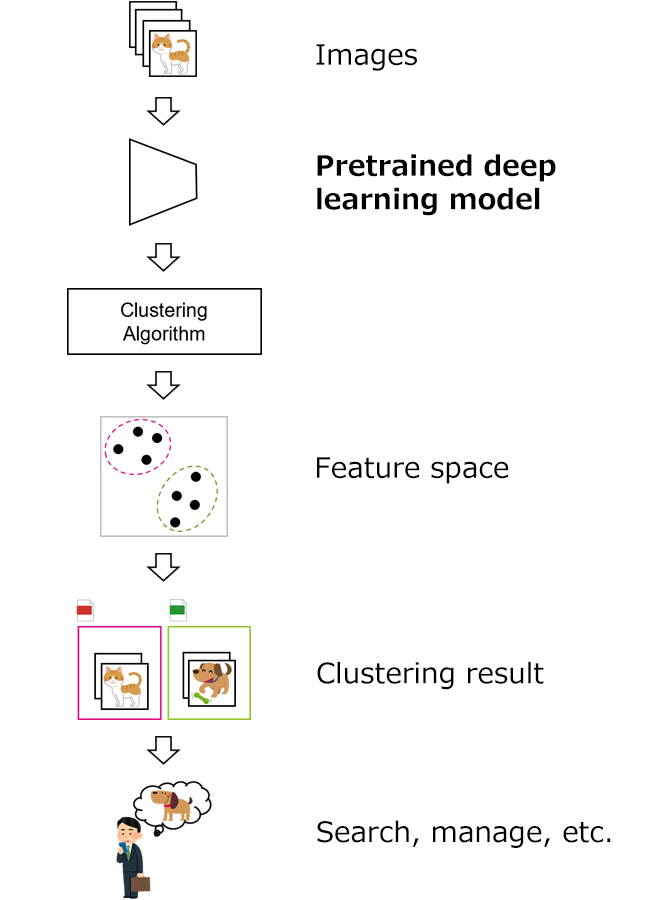
In today's world, we generate and manage vast amounts of image data through smartphones and cloud services. To efficiently search and organize this wealth of image data for our daily tasks and work, accurate image recognition technologies, including image clustering methods, are crucial. Image clustering refers to the technique of grouping large sets of image data based on similarities. Figure 1 illustrates an application of image clustering technology. When image data is processed by a trained deep learning model, each image is transformed into a vector representation. These vectors exist in a high-dimensional space known as feature space, which is not interpretable by humans but can be categorized into groups using clustering algorithms. Results classified in feature space are also useful for person recognition in smartphone photo applications.

In recent years, deep learning models have been pre-trained on large datasets to enhance image recognition accuracy, with the Vision Transformer (ViT) gaining attention as a powerful architecture for such models (e.g., DINOv2[1]). While ViT has demonstrated high performance across various vision tasks, including image recognition, object detection, and image generation, its effectiveness in clustering tasks has been less satisfactory[2]. To improve the clustering accuracy of ViT models, we developed an approach called Inference-Time Attention Engineering (ITAE) [2].
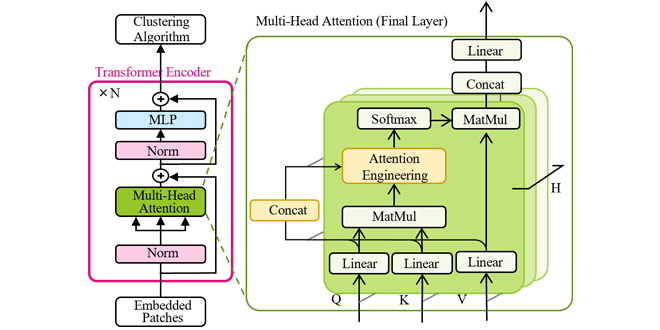
Figure 2 provides an overview chart of ITAE. This method extends ViT, adding components highlighted in yellow. The ViT architecture includes (1) a feature vector that represents the characteristics of the entire image (referred to as the whole image vector VCLS) and (2) feature vectors corresponding to individual subregions (referred to as subregions image vector VCLS). ITAE enhances image clustering performance by automatically identifying anomalies in the ViT model that negatively impact the whole image vector VCLS and treating them effectively.
The inspiration for this research stemmed from earlier work that focused on the individual subregion vectors Vi produced by the ViT model. This previous study noted that large output anomaly vectors in certain subregions degraded the model's accuracy across various tasks[3]. Improving these anomalies also led to better overall performance. However, since the focus was on subregion vectors, the accuracy improvement for clustering tasks using the whole image vector VCLS was limited. Therefore, we directed our attention to internal anomalies within the model to further enhance clustering accuracy. In the following sections, we first explain how ViT operates, followed by the detailed methodology we have developed.
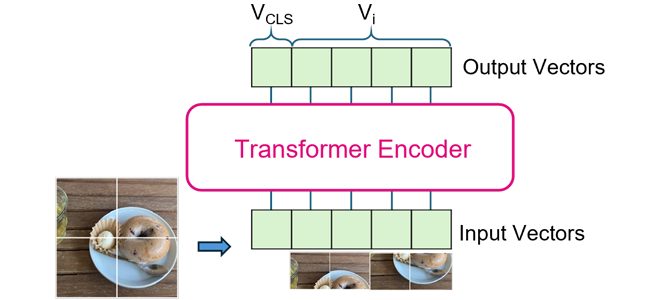
Figure 3 depicts the image processing flow in ViT, where the input image is divided into subregions, each producing a feature vector Vi. Simultaneously, a special vector VCLS representing the entire image is generated. These vectors are output after being processed by the Transformer Encoder, which consists of N layers, all sharing a similar structure.
Within the Transformer Encoder, the Multi-Head Attention mechanism used in ITAE enables the simultaneous input of all vectors (VCLS, Vi), allowing for individual updates at the output. To clarify the computation involved in Multi-Head Attention, Figure 4 shows a simplified diagram of the calculation of one head of Multi-head. Specifically, the Attention values are computed to measure the relationships between the whole image vector VCLS and all vectors (VCLS, Vi)(A). Each Attention value is a single real number representing the correlation, subsequently weighted and summed to compute the updated whole image vector VCLS. Thus, the new VCLS (C) is an aggregated weighted sum of all vectors (VCLS, Vi) (B), where the weights reflect the Attention values that quantify the associations between the vectors.
We studied the behavior of the subregions within Multi-Head Attention where anomalies had previously been noted[3] and discovered that these regions also exhibited abnormal features in their vectors—as they had lengths significantly exceeding those of other vectors. Such internal anomalies negatively impacted both the whole image vector VCLS and the individual subregion vectors Vi. Consequently, we believed that addressing these internal anomalies would further improve clustering accuracy.
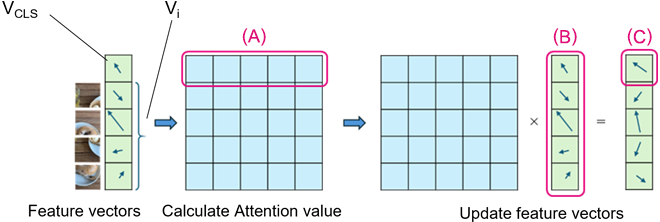
Rather than directly eliminating the internal anomalies through retraining, ITAE strategically reduces the weights assigned to these anomalous regions by lowering their Attention values (as illustrated in Figure 5). In the Multi-Head Attention of the last layer of the Transformer Encoder, the lengths of the vectors before updating are assessed to identify the problematic small regions (D). Their corresponding Attention values are then attenuated(E), resulting in an updated whole image vector VCLS (F).
Since the Attention value effectively determines the influence of the different regions on VCLS, decreasing the Attention values of the anomalous regions minimizes their impact, enabling the model to allocate attention more appropriately across the remaining regions. Importantly, this adjustment does not necessitate retraining and can be seamlessly implemented during inference.
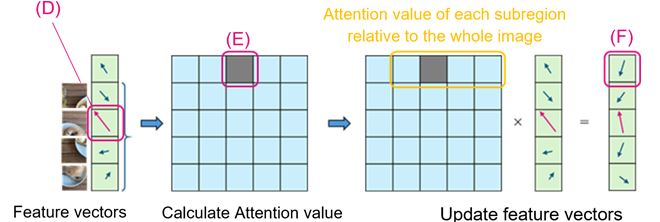
Figure 6 overlays the Attention values for each sub-region (highlighted in orange boxes of Figure 5) on the image in reference to VCLS. The color gradient from blue to yellow indicates ascending Attention values. The central image illustrates how the ViT model allocated Attention values throughout the actual image, revealing areas of high Attention in the background, which typically lack significant objects. Thus, since anomalous feature vectors tend to reside in regions displaying elevated Attention values, applying ITAE to reduce these values is likely to improve Attention distribution significantly.

The modification of Attention values through ITAE effectively mitigates the adverse effects of model anomalies, leading to enhanced outputs of VCLS and improved clustering accuracy in validation experiments. Our experiments utilized datasets like CIFAR-10[4], CIFAR-100[4], STL-10[5], and Tiny ImageNet[6], comparing the clustering accuracies of conventional models[1][3] with those incorporating ITAE. Clustering accuracy is measured by the alignment of predicted groupings with correct groupings, where 100% signifies perfect correspondence. Notably, ITAE yielded average improvements in clustering accuracy of 1.66% over Method 1 and 5.05% over Method 2, underscoring the direct correlation between mitigating internal anomalies within Multi-Head Attention and improved clustering performance.
The primary advantages of ITAE lie in its efficiency and ease of use; it does not require retraining or additional training of existing large-scale pre-trained models, and it can run efficiently within a single inference pass, making it an accessible and effective solution for enhancing ViT models' performance.
* Table can be scrolled horizontally.
|
Dataset |
CIFAR-10[4] |
CIFAR-100[4] |
STL-10[5] |
Tiny ImageNet[6] |
|---|---|---|---|---|
|
Conventional1[1] |
82.16 |
68.69 |
65.78 |
71.98 |
|
Conventional2[3] |
78.67 |
68.01 |
56.84 |
71.53 |
|
Ours |
82.49 |
69.04 |
70.51 |
73.19 |
This achievement was presented at the Asian Conference on Computer Vision 2024(ACCV2024)[2].
This material is a partial excerpt and a reconstruction of Ref [2] ©2025 Springer.
Company names, product names, and service names may be trademarks of third-party companies.
Reference
[1] Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning Robust Visual Features without Supervision. Transactions on Machine Learning Research (2024)
[2] Nakamura, K., Nozawa, Y., Lin, Y. C., Nakata, K., Ng, Y.: Improving Image Clustering with Artifacts Attenuation via Inference-Time Attention Engineering. In: In Asian Conference on Computer Vision (pp. 277-295). Springer, Singapore. (2025)
[3] Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision Transformers Need Registers In: The Twelfth International Conference on Learning Representations (2024)
[4] Krizhevsky, A., Hinton., G.: Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto (2009)
[5] Coates, A., Ng, A., Lee, H.: An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. pp. 215–223. JMLR Workshop and Conference Proceedings (2011)
[6] Le, Y., Yang, X.: Tiny ImageNet Visual Recognition Challenge. CS 231N 7(7), 3 (2015)

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.