Please select your location and preferred language where available.
Development of high-speed and high-energy-efficiency algorithm and hardware architecture for deep learning accelerator
February 28, 2019
We have developed an AI accelerator for deep learning and presented it at an International conference on semiconductor circuits, A-SSCC 2018.
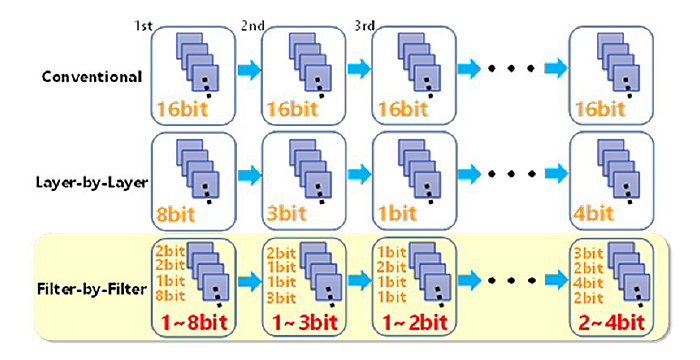
Huge numbers of multiply-accumulate (MAC) computations are required for deep learning, but they give rise to long computation time and large power consumption. In order to cope with them, we introduced two new techniques: “filter-wise optimized quantization with variable precision” (Fig. 1) and “bit parallel MAC hardware architecture.” (Fig. 2)
The filter-wise technique optimizes the number of weight bits for each one of tens or thousands of filters on every layer. If the average bit precision is 3.6bit, the recognition accuracy of layer-wise optimized quantization (Fig. 1 middle) is reduced to less than 50%, but the proposed filter-wise quantization maintains almost the same accuracy as that before quantization with reduced computation time.
The bit serial technique (Fig. 2 left) is often used for MAC architecture, but if it is applied to filter-wise quantization (Fig. 2 middle), the execution time will vary depending on the bit precision of filters. The PE (Processing Element) assigned for the filter whose computation is large may become a bottleneck. The bit parallel technique (Fig. 2 right), on the other hand, divides each various bit precision into a bit one by one and assigns them to several PEs one by one and operates them in parallel. The utilization efficiency of PEs is improved to almost 100% and throughput also becomes higher.
We implemented our algorithm and hardware architecture with ResNet-50*1 on FPGA*2 and demonstrated the image recognition test of ImageNet*3 run with 5.3 times computation throughput and with computation time and energy consumption as low as 18.7%.

- ResNet-50: One of deep neural network, generally used to benchmark deep-learning for image recognition
- FPGA: Field Programmable Gate Array
- ImageNet: A large image database, generally used to benchmark image-recognition, the number of image data is over 14,000,000.

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.