Please select your location and preferred language where available.
現代社会において私たちは、スマートフォンやクラウドサービスを通じて膨大な画像データを扱っています。日々の生活や業務において、その膨大な画像データを目的に応じて効率的に検索・整理するためには、画像クラスタリング技術を含めた、高精度な画像認識技術が不可欠です。画像クラスタリング技術とは、膨大な画像データを類似したデータごとにグループ化(クラスタリング)する技術です。図1に画像クラスタリング技術の応用例を示しています。画像データを学習済み深層学習モデルに通すと、入力された画像データそれぞれが、ベクトルに変換されます。このベクトルは特徴量空間と呼ばれる非常に高次元の空間のベクトルのため、人間には解釈できませんが、クラスタリングアルゴリズムを使うことで、それぞれのグループに分けることができます。特徴量空間上で分類された結果は、スマートフォンの写真アプリにおける人物認識などにも使われています。近年、画像認識の高精度化を実現するため、大規模なデータセットを用いた深層学習モデルの事前学習が行われています。この流れの中で、Vision Transformer(ViT)が深層学習モデルのアーキテクチャとして注目を集めており、活発に研究が進められています(例:DINOv2[1])。ViTは入力された画像を小さな領域に分割し、これらの小領域同士の関係を解析しながら、画像全体の特徴を抽出するアーキテクチャです。ViTは画像認識、物体検出、画像生成などのさまざまなビジョンタスクにおいて高い性能を示します[1]が、クラスタリングタスクにおいて性能が不十分でした[2]。そこで当社は、推論時アテンションエンジニアリング(ITAE)という新たな手法を開発し、ViTモデルのクラスタリング精度の向上を達成しました[2]。

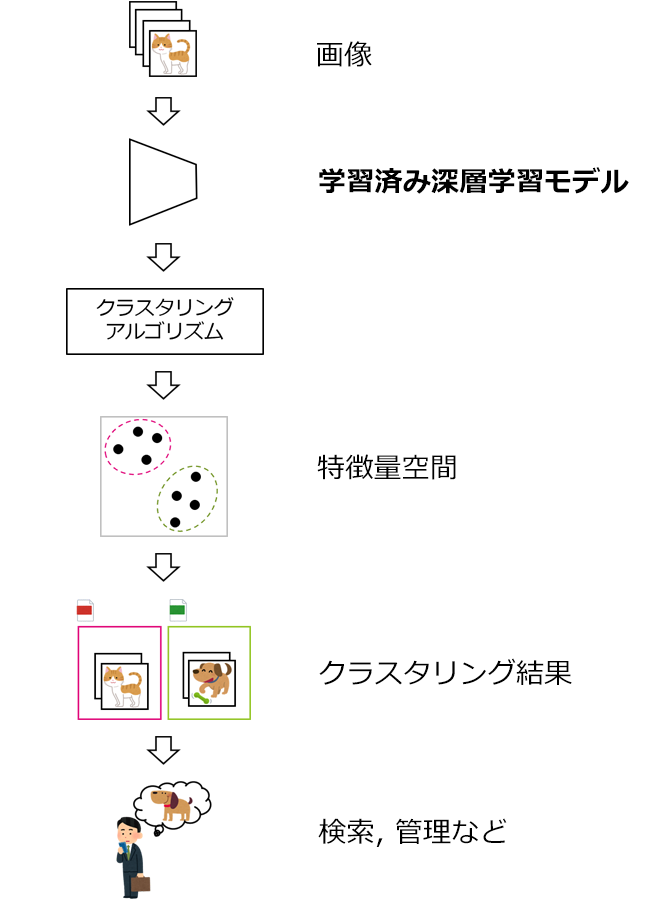
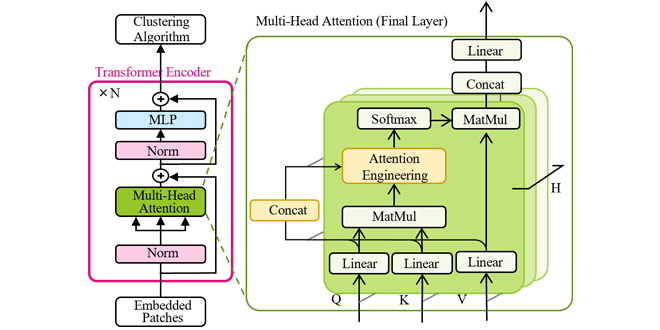
図2はITAEの概要図です。ITAEはViTを拡張したものであり、黄色い枠で囲まれたブロックがViTに追加された部分です。ViTは、(1)画像全体の特徴を表す特徴量ベクトルVCLS(以降、画像全体ベクトルVCLSと表記)と(2)各小領域に対応する特徴量ベクトルVi(以降、各小領域ベクトルViと表記)の二種類の情報を出力する仕組みになっています。ITAEは、画像全体ベクトルVCLSに悪影響を与えるViTモデル内部における異常を自動的に判別、これを適切に処理することで、画像クラスタリングの性能を向上する手法です。以下では、ITAE開発に至った経緯と手法ついて説明します。
今回の研究のきっかけは、ViTモデルの出力のうち各小領域ベクトルViに注目した先行研究にあります。この研究では、各小領域の一部に極端に大きな出力異常ベクトルが発生し、様々なタスクの精度を悪化させていることが報告されており、その異常を改善することによってモデルの性能を向上させています[3]。この研究は、二つの出力のうち各小領域ベクトルViに焦点を当てているため、画像全体ベクトルVCLSを利用するクラスタリングタスクにおける精度改善は限定的でした。このため、当社はクラスタリングの精度を更に向上させるべく、モデルの内部異常に注目しました。以下ではまずViTの仕組みについて述べ、その後今回開発した手法について説明します。
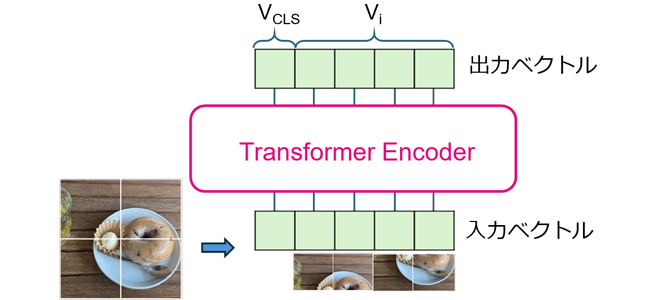
図3はViTにおける画像処理の流れを示した図です。ViTは入力された画像をまず小領域に分割し、各小領域で入力画像を特徴量ベクトルViに変換します。この時、画像全体を表す特別なベクトルVCLSも追加されます(入力ベクトル)。これらのベクトルはTransformer Encoderでの処理を経て出力されます(出力ベクトル)。Transformer Encoderは図2のピンクの枠内のまとまりをN層重ねたもので構成され、すべての層は同様の構造を持ちます。
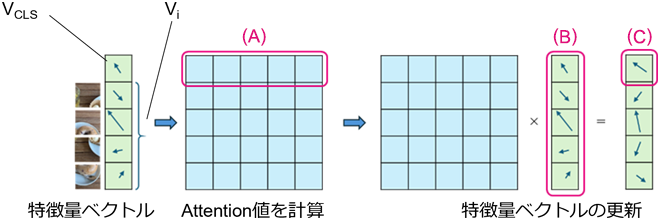
特に、ITAEで利用するTransformer Encoder内部のMulti-Head Attentionでは、全ベクトル(VCLSとVi)が同時に入力され、出力時にはそのすべてがそれぞれ更新されます。Multi-Head Attentionは名前の通り、複数のヘッドを持つモジュールです。各ヘッドで一連の計算を行い、それを並列したものがMulti-Head Attentionです。Multi-Head Attentionの計算の肝となる部分を説明するため、図4にMulti-Head Attentionの一つのヘッドの計算を簡略化して示しました。理解のために、画像全体ベクトルVCLSがどう更新されるのかを考えます。まず、画像全体ベクトルVCLSと全ベクトル(VCLSとVi)が相互にどの程度関連しているかの指標であるAttention値(図4(A))を計算します。Attention値は全ベクトル(VCLSとVi)のそれぞれに対して一つの実数として計算されます。その後、Attention値と全ベクトル(VCLSとVi)(図4(B))を掛け合わせる(重み付き和、図2のMatMulに対応)ことにより最終的に目的の新しい画像全体ベクトルVCLS(図4(C))が計算されます。つまり、新しい画像全体ベクトルVCLSは、全ベクトル(VCLSとVi)の重み付き和として更新され、その重みには画像全体ベクトルVCLSと全ベクトル(VCLSとVi)の関連度を数値化したAttention値という値が使われます。各領域ベクトルViのそれぞれに対しても上記の画像全体ベクトルVCLSの更新と同様の計算を行います。
先行研究[3]で指摘された出力異常の発生する小領域がMulti-Head Attention内部でどのように振舞っているのかを調べたところ、当該小領域はMulti-Head Attention内部の特徴量ベクトルにおいても異常な振る舞い(=ベクトルの長さが、他の大多数の小領域のベクトルの長さよりも極端に大きい)をしていることが分かりました。ViTモデルのこの内部異常はモデルの出力画像全体ベクトルVCLSと各小領域ベクトルViの両方に悪影響を与えます。そこで当社はViTモデルの内部異常に対処することで、画像全体ベクトルVCLSを利用するクラスタリングの精度を更に向上させることができると考え、ITAEを開発しました。
ITAEのアプローチは、この内部異常の発生を再訓練や追加の学習によって直接防ぐのではなく、重み付き計算における重みを強制的に小さくする、つまり異常な小領域のAttention値を減少させるというものです(図5)。図5はITAEの計算の簡略図です。Transformer Encoder最終層(N層目)のMulti-Head Attentionにおいて、更新前のベクトルの長さを計算し、長さの大きい異常な小領域(図5の(D))を特定します。そして、対応するAttention値(図5の(E))を減衰させます。計算の結果、修正された画像全体ベクトルVCLS(図5の(F))が得られます。先に述べたようにAttention値は全ベクトル(VCLSとVi)のそれぞれを、全ベクトル(VCLSとVi)の重み付き和として更新するために利用されます。例えば画像全体ベクトルVCLSに対して、ある小領域に対応するAttention値が大きければ、その小領域は画像全体ベクトルVCLSに大きな影響を与えます。これは逆に、ある小領域のAttention値を強制的に小さい値に変更すればその小領域の影響が減るということであり、ITAEはこれを異常な小領域に適用しています。実際の計算ではAttention行列は各行の合計が1になるように調整されるため、異常な小領域のAttention値を減少させると、その他の小領域のAttention値は自動的にITAE適用前よりも大きくなります。これにより、内部異常が画像全体の特徴量へ与える悪影響を軽減し、より適切な小領域へAttention値が割り振られるようになります。このAttention値に対する変更は、モデルの再訓練や追加の学習を必要とせず、推論を行う際に容易に実装することができます。
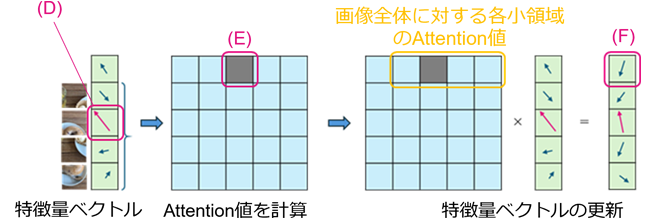
図6は、画像全体ベクトルVCLSに対する各小領域のAttention値(図5のオレンジの枠)を画像の上に重ねた図です。色が青から黄色に変わるほどAttention値が大きいことを示しています。中央の図は実際の画像にViTモデル[1]がどのようにAttention値を振り分けたのかを示しており、特に物体のない背景部分にAttention値の大きな小領域が存在していることが分かります。これは画像全体ベクトルVCLSが、背景部分に影響を受けていることを示しています。異常値を示す特徴量ベクトル分布は、このような特に物体のない背景部分にも関わらずAttention値が大きくなっている小領域とほとんど一致するため、ITAEの適用によって異常な小領域のAttention値を減少させることで、副次的にAttention値の分布が改善します。右側の図は同じモデルにITAEを適用した場合のAttention値の分布です。ベーグルや鳥といった、画像全体の特徴量に影響を与える物体として直感的に正しい物体の小領域にAttention値が振り分けられていることが分かります。

ITAEは上記ViTモデル内部異常の自動判別とその悪影響の低減処理によって、より正確な画像全体ベクトルVCLSの出力を可能にし、検証実験における画像クラスタリング精度向上を実現しました。実験では、データセットとしてCIFAR-10[4]、CIFAR-100[4]、STL-10[5]、Tiny ImageNet[6]を用い、従来のモデル[1][3]とITAEを適用したモデルのクラスタリング精度を比較しました(表1)。画像クラスタリングは、モデルにグループ分けされた画像セットをグループの情報を与えずに入力し、正しいグループ分けを予測するタスクです。精度はそれらのグループ分けが本来のグループ分けとどれだけ一致しているか(%)で表され、完全に一致していれば100%となります。追加の学習をしなくとも、ITAEはデータセット平均で、従来手法1から1.66%、従来手法2から5.05%のクラスタリング精度の向上を達成しました。この結果は、Multi-head Attention内部の異常の影響を低減することが、クラスタリング精度の向上に直結することを示しています。
ITAEの主な利点は、既存の大規模事前学習済みモデルに対して再訓練や追加の学習を必要としないことや、一度の推論で処理が行えるために計算効率が高いことです。大規模な計算リソースが不要なことによって導入しやすい技術となっています。
※表を左右にスクロールすることができます
|
Dataset |
CIFAR-10[4] |
CIFAR-100[4] |
STL-10[5] |
Tiny ImageNet[6] |
|---|---|---|---|---|
|
従来手法1[1] |
82.16 |
68.69 |
65.78 |
71.98 |
|
従来手法2[3] |
78.67 |
68.01 |
56.84 |
71.53 |
|
当社の手法 |
82.49 |
69.04 |
70.51 |
73.19 |
本成果は2024年12月に開催されたコンピュータビジョン分野のトップの国際会議の1つであるAsian Conference on Computer Vision 2024(ACCV 2024)にて発表されました[2]。
本稿は、文献[2]©2025 Springerから図面等一部抜粋&再構成したものです。
記載されている社名・商品名・サービス名などは、それぞれ各社が商標として使用している場合があります。
文献
[1] Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning Robust Visual Features without Supervision. Transactions on Machine Learning Research (2024)
[2] Nakamura, K., Nozawa, Y., Lin, Y. C., Nakata, K., Ng, Y.: Improving Image Clustering with Artifacts Attenuation via Inference-Time Attention Engineering. In: In Asian Conference on Computer Vision (pp. 277-295). Springer, Singapore. (2025)
[3] Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision Transformers Need Registers In: The Twelfth International Conference on Learning Representations (2024)
[4] Krizhevsky, A., Hinton., G.: Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto (2009)
[5] Coates, A., Ng, A., Lee, H.: An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. pp. 215–223. JMLR Workshop and Conference Proceedings (2011)
[6] Le, Y., Yang, X.: Tiny ImageNet Visual Recognition Challenge. CS 231N 7(7), 3 (2015)

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。