Please select your location and preferred language where available.
今年2月に米国サンフランシスコで開催されたISSCC2025にて、BiCS FLASH™ 第10世代となる1Tb 3bit/cellのチップの発表を行いました。このチップは、キオクシア株式会社とサンディスクコーポレーションで共同開発されており、ワード線(以下WL)積層数を332層に高積層化しつつ、レイアウト最適化技術により、1Tb製品の中で世界最高の29Gb/mm2の記録密度、世界最小のチップ面積を実現しています。また、最新のToggle DDR 6.0採用に加え、新インターフェース(以下IF)回路方式と読み出し方式の採用により、データ転送速度4.8Gbpsと、読み出しの特定動作時に29%の消費電力削減を達成しています。今回は、レイアウト技術とIF回路技術、CORE読み出し性能向上技術の3つの観点でそれぞれ概要を紹介します。
レイアウト技術
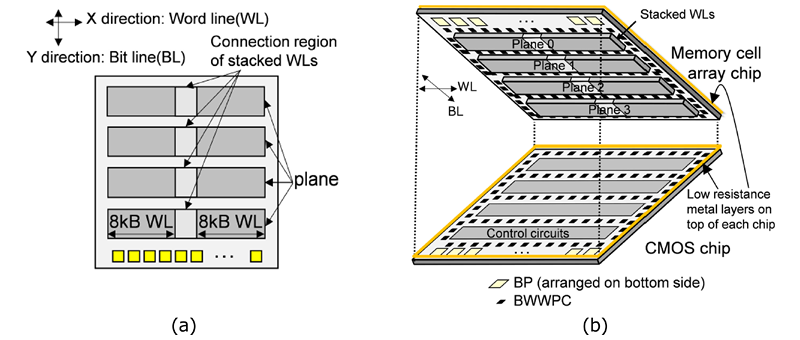
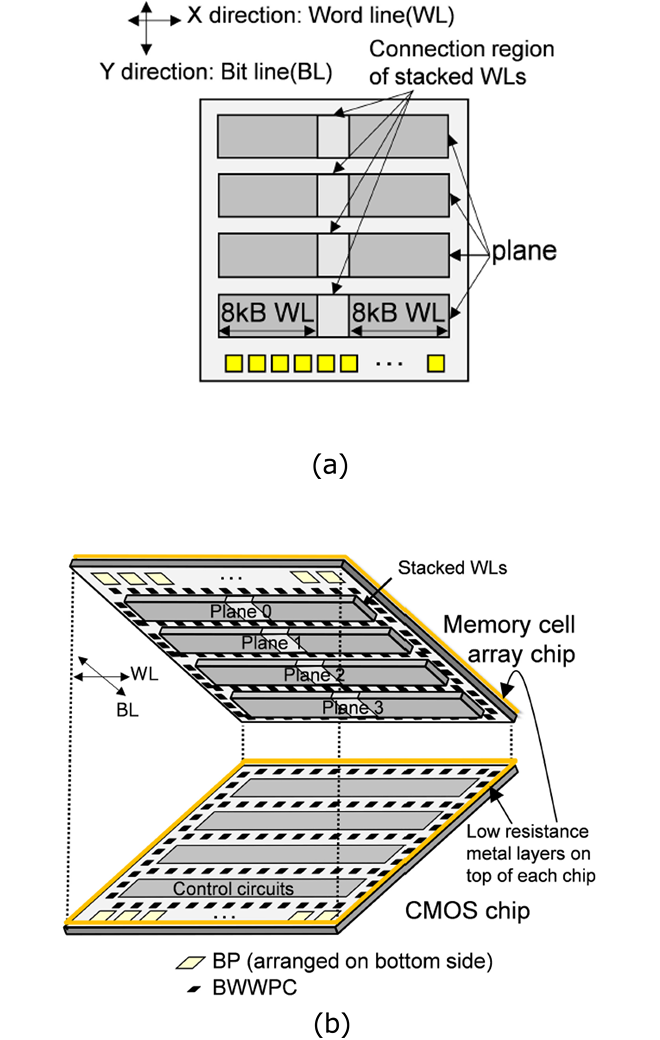
本製品では従来製品同様にCBA(CMOS directly Bonded to Array)構造を採用していますが、今回はチップY方向に4つのプレーンを並べるフロアプランを採用し、これまでオーバーハングとなっていたボンディングパッド(BP)領域の面積を削減しています(図1(a))。また、図1(b)に示すようにMemory cell arrayチップとCMOSチップの最上層メタル配線に低抵抗メタル配線を使用し、チップ間を接続するボンディングパッド(Bonding pads for Wafer-to-Wafer Power Connection:BWWPC)で効率的に接続することで、チップ全体で強固な電源ネットワークを築いています。これらのフロアプラン、レイアウト技術により、回路のWL(X direction)とBL(Y direction)方向に凝縮配置を可能にし、大幅な面積効率の改善や回路性能の改善を実現しています。
インターフェース技術
図2(a)にUnmatched DQSのIF構成を示します。各DQのInput Receiver(IREC)で使用する参照電圧VREFi[i]には、別々に電圧を生成、トレーニング設定できるPer Pin VREF Training(以下PPVT)構成を採用しつつ、Data-Driven Self-Reset(DDSR)回路付き2-way Time Interleaved - Decision-Feedback Equalizer(以下2TI-DFE)を導入しています。図2(b)に回路図の概要、図2(c)にタイミングチャートを示します。DRAMでよく知られている4TI-DFEはデータ取り込みマージンを改善する技術ですが、各DQに対して 4つのセンスアンプが必要となり、回路消費電力と回路面積の増加が懸念でした。本製品ではDDSR回路を新たに導入したことで、Even側のセンスノードである3入力NANDの1PE and 1ME が変化するまで、Odd側の出力ノードOPO、OMOにある出力結果を保持することができるため、短いインターバルを最大限有効に使いデータのフィードバックが可能となっています。本DDSR回路付き2TI-DFEは、従来型の4TI-DFEに対して消費電力と回路面積の削減を実現しています。
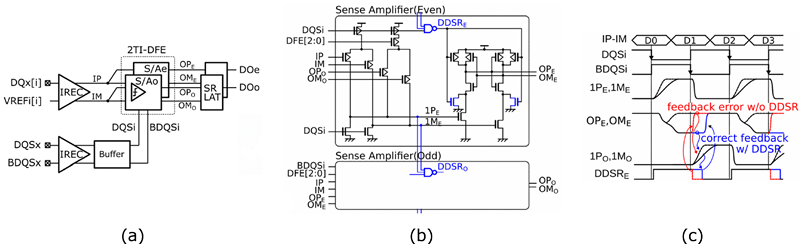
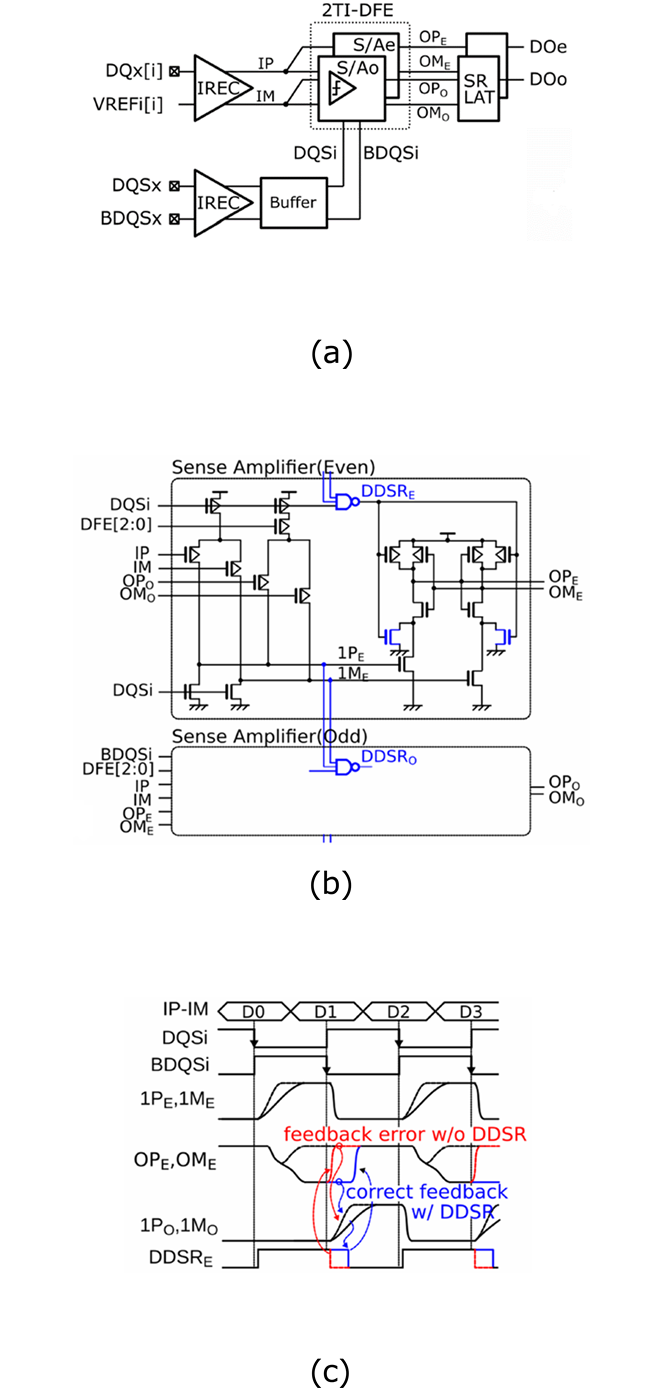
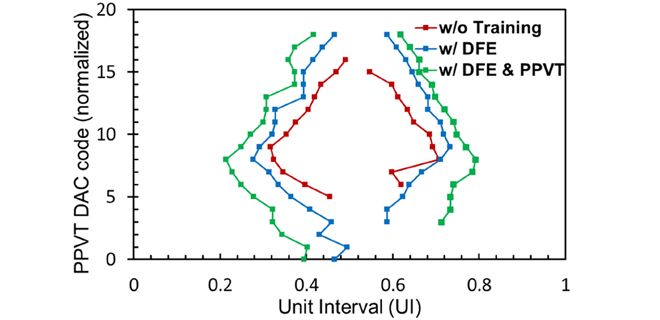
図3に全DQを含んだシュムープロットを示します。横軸は時間の単位、縦軸はVREFの設定電圧を示しており、各色のプロットで囲まれた領域がデータウィンドウを示しており、このウィンドウが広いほどデータ取り込みマージンが大きいことを意味しております。赤色はDFEとPPVT共に使用無し、青色はDFEのみ使用、緑はDFEとPPVTの両方使用した場合の結果を示しています。2TI-DFEとPPVTを活用した場合、従来手法よりもデータウィンドウの拡幅を実現でき、データ転送速度4.8Gbpsを達成しています。
CORE読み出し性能向上技術
WL高積層化に伴い増加する非選択WLの充電が読み出し時間と消費電流の増加の大きな要因となっています。連続する読み出し動作においてこの問題を解決するために、WLの電位変化を縮小し性能を改善する技術を導入しています。図4に従来技術と本技術の波形比較を示しています。従来技術では、連続するRead動作のインターバルで非選択WLはVSSとチャージポンプで生成される電圧(Vread)まで変化しており、充放電動作が入り、消費電流が増加しておりました。この課題を解決するため、本技術では最初のWL読み出し動作後に非選択WLをVSSよりも高い中間電位に対して放電を行います。このように動作させることにより、次のRead動作で非選択WLのVreadまでの立ち上げ時間と充電電荷量の削減を実現しています。
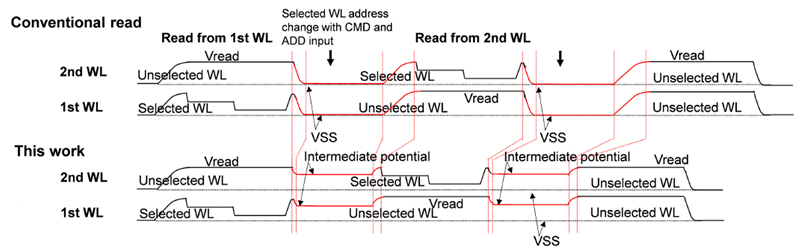
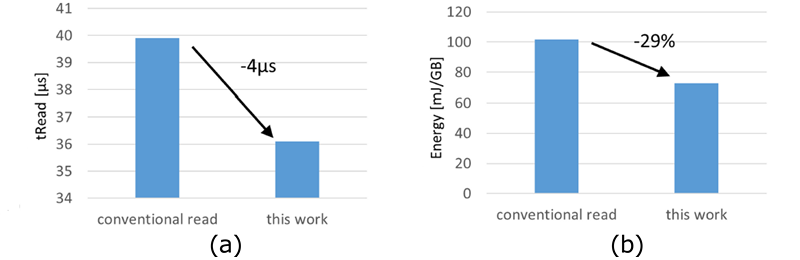
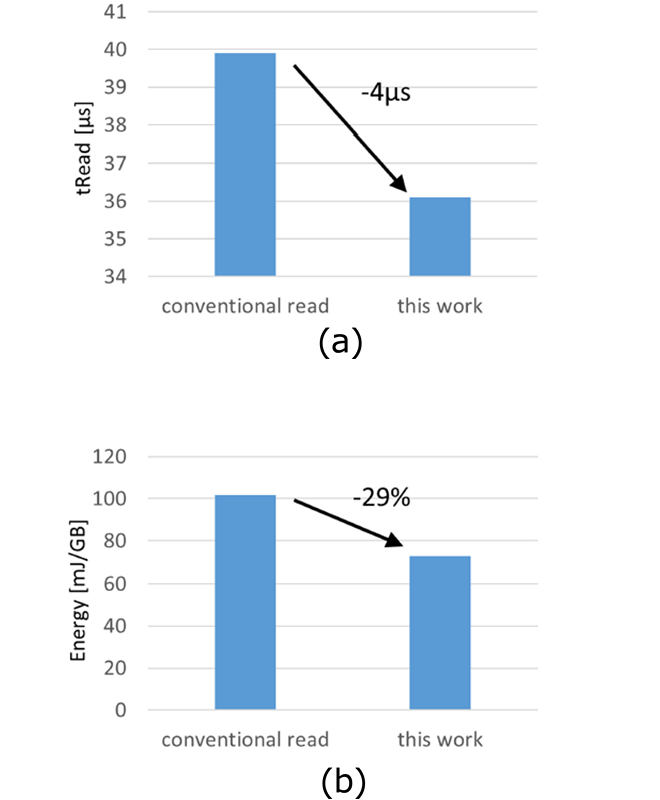
図5(a)に読み出し時間の比較、図5(b)に電力効率の比較を示します。本技術により、連続Read動作時の読み出し時間の4us改善、電力効率29%改善を実現しています。
以上のようにZ方向へのWL高積層技術に加え、X、Y方向を凝縮した回路・レイアウト技術と、高速動作を実現しつつ消費電力の低減を行う回路技術を導入した製品の開発に成功しました。今後も更なる低消費電力回路を実現しながら、それと同時にフラッシュメモリの高性能・大容量化に向け貢献してまいります。
本成果は2025年2月に開催されたISSCC2025において発表されました。
文献
[1] K. Yanagidaira et al., “30.2 A 1Tb 3b/cell 3D Flash Memory with a 29%-Improved-Energy-Efficiency Read Operation and 4.8Gb/s Power-Isolated Low-Tapped-Termination I/Os,” ISSCC, pp506-507, 2025. © 2025 IEEE

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。