Please select your location and preferred language where available.
Approaching DRAM performance by using microsecond-latency flash memory for small-sized random read accesses: a new access method and its graph applications
September 28, 2021
Graph processing is one of the most important data processing employed in various applications such as social network analysis (for recommendations in SNS, or for fake news detection), computer network analysis, and bioinformatics. In the modern "big data" era, we handle very large scale graph. When the graph size exceeds DRAM capacity, one of solutions is to utilize SSDs. However, conventional SSDs cannot efficiently process several graph algorithms that contain many random accesses with fine granularity of several to hundreds of bytes. For example, simply using SSD as virtual memory, graph processing can be about 1/100 the speed of using DRAM. Even if access is optimized by software, it will be still about 1/10.
We introduced high-speed flash memory (XL-FLASH™) [1] and developed a new access method for it, achieving the equivalent speed as keeping all graph data in DRAM. This enables high-speed processing for very large-scale graph with flash memory at lower cost than DRAM. This achievement was presented at Very Large Data Bases (VLDB) 2021.
The technical details are described below.
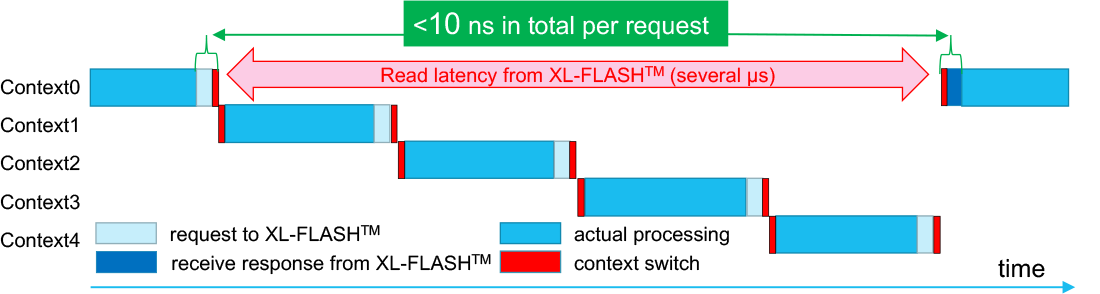
KIOXIA developed low latency flash memory, XL-FLASH™ , and a prototype board using XL-FLASH™ (Figure 1) provides one order of magnitude more random read access performance than conventional SSDs, and faster processing is possible. However, as the number of read requests per second increases, the percentage of CPU time to issue read requests and confirm the completion of the requests increases in the whole process. Therefore, it is important to reduce CPU time for issuing requests and confirming the completions for each access. We developed a new access method that uses two techniques to reduce CPU overhead. The first technique is to modify the existing SSD NVMe™ IF protocol to reduce CPU time (Figure 2). The second technique is, in order to reduce the switching time (time to switch contexts) for the CPU, to execute other processing while waiting for XL-FLASH™ data to be read. These method allows read access to be executed with a CPU load overhead of less than 10ns per access (Figure 3).

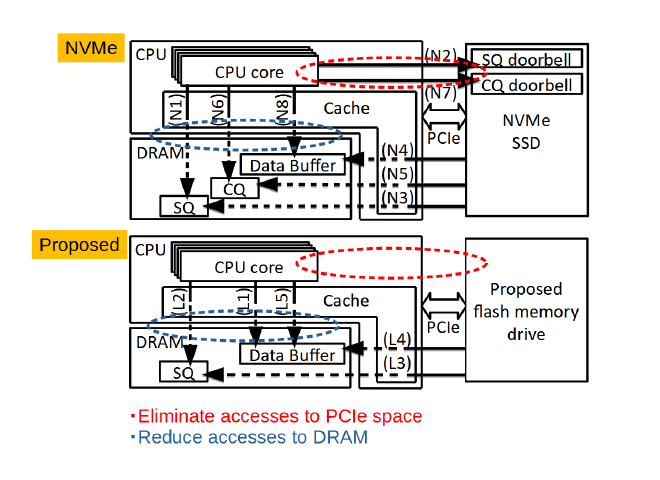
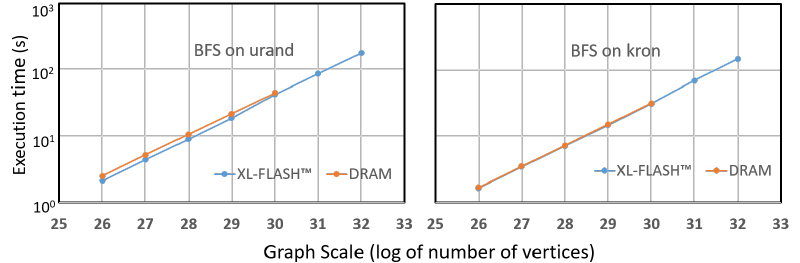
In order to evaluate the application of the proposed access method to large scale graph processing, the execution time in two environments was compared: one is when most of the graph data is placed on XL-FLASH™, and the other is when all the data is placed on DRAM (Figure 4). The result showed the two case can be performed in similar run time, for typical graph algorithms, such as Breadth-first search (BFS) on the graph.
In addition, systems using XL-FLASHTM can process graph sizes that cannot be by DRAM without significantly increasing execution time. The execution times are within expected ones for very large scale graphs. This result is an example of applying the proposed access method to graph processing, but we think that it can be applied to applications other than graph processing that provide random access to large-scale data.
This article is reconstructed from an excerpt of reference[2] presented at VLDB2021 held in August 2021.
PCIe is a registered trademark of PCI-SIG.
NVMe is a registered or unregistered mark of NVM Express, Inc. in the United States and other countries.
All other company names, product names, and service names may be trademarks of their respective companies.
[1] Kioxia press release, August 5, 2019
http://americas.kioxia.com/en-us/business/news/2019/memory-20190805-1.html![]()
[2] T. Suzuki et al., Approaching DRAM performance by using microsecond-latency flash memory for small-sized random read accesses: a new access method and its graph applications. Proceedings of the VLDB Endowment 14, 8 (2021), 1311 - 1324

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.